Our team works on extracting various modalities of information from research papers, such as line charts, tables, and key phrases. The following projects address fundamental challenges in the digital processing of academic documents. This work not only enhances the efficiency of academic research by making data more readily accessible and analyzable but also supports meta-analyses of content of research paper that is not present in straightforward text format. Overall, the motivation is to advance the accessibility and utility of scientific knowledge.
LineEX: Data Extraction from Scientific Line Charts
Tables to Latex: Structure and context extraction from scientific tables
SEAL: Scientific Keyphrase Extraction and Classification
TabLeX: A Benchmark Dataset for Structure and Content Information Extraction from Scientific Tables
LLMs and Scientific Texts
We are highly interested in understanding the behavior and capabilities of domain-specific scientific language models such as SciBERT, OAG-BERT, SPECTER, Galactica, etc., alongside state-of-the-art large language models such as GPT-4, Llama 2, Mistral, etc. for tasks that require comprehension of scientific texts such as peer reviews and research papers.
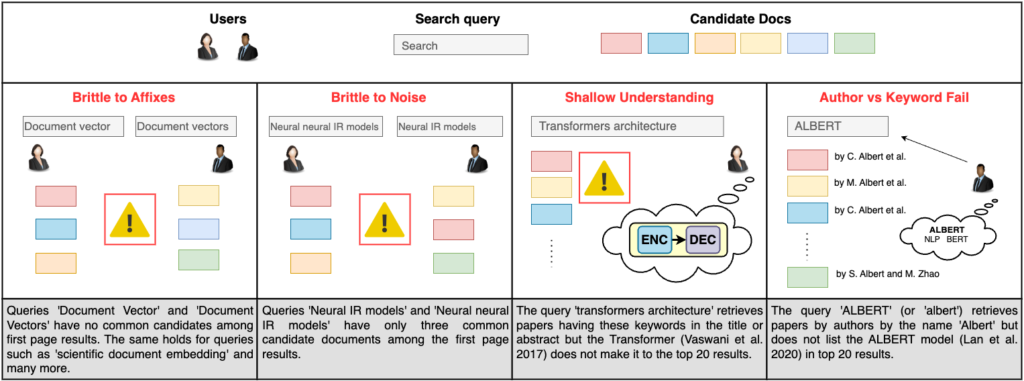
The Inefficiency of Language Models in Scholarly Retrieval: An Experimental Walk-through
CoSAEmb: Contrastive Section-Aware Embeddings for Research Papers
Our team places great emphasis on the importance of datasets for the training and evaluation of AI models. We have curated a collection of datasets designed for a range of scientific endeavors, including LEGOBench for leaderboard generation, datasets aimed at facilitating the automatic generation of model cards, a dataset focused on the analysis of empirical comparisons in peer reviews, and a dataset capturing scientific discourse from Twitter.
Unlocking Model Insights: A Dataset for Automated Model Card Generation
COMPARE: A Taxonomy and Dataset of Comparison Discussions in Peer Reviews
TweetPap : A Dataset to Study the Social Media Disclosure of Scientific Papers
Tools and Portals
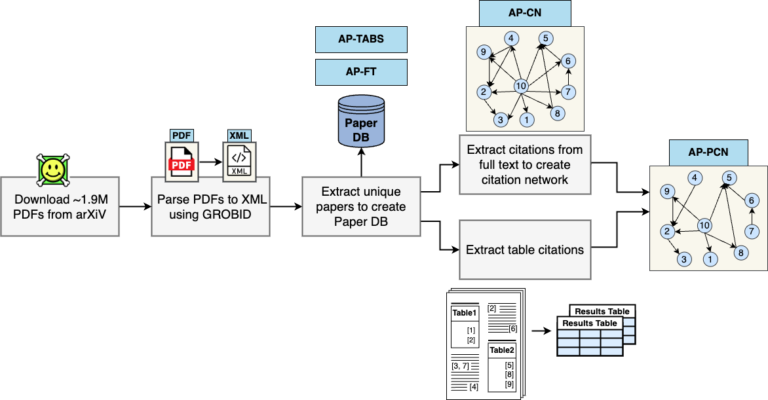
We have built OCR++, an open-source framework for information extraction from scholarly articles. NLPExplorer is a completely automatic portal for indexing, searching, and visualizing Natural Language Processing (NLP) research volume. NLPEXPLORER presents interesting insights from papers, authors, venues, and topics. In contrast to previous topic modelling based approaches, we manually curate five course-grained non-exclusive topical categories namely Linguistic Target (Syntax, Discourse, etc.), Tasks (Tagging, Summarization, etc.), Approaches (unsupervised, supervised, etc.), Languages (English, Chinese, etc.) and Dataset types (news, clinical notes, etc.). NLPExplorer has been accessed by more than 7.3K unique users having close to 9.7K sessions.
OCR++: A Robust Framework For Information Extraction from Scholarly Articles
NLPExplorer: Exploring the Universe of NLP Papers
TweeNLP: A Twitter Exploration Portal for Natural Language Processing
CovidExplorer: A Multi-faceted AI-based Search and Visualization Engine for COVID-19 Information
ACL Scholar: The ACL Anthology Knowledge Graph Miner
Others
Automated early leaderboard generation from comparative tables
Relay-linking models for prominence and obsolescence in evolving networks
AppTechMiner: Mining Applications and Techniques from Scientific Articles
FeRoSA: A Faceted Recommendation System for Scientific Articles PAKDD
Genealogical Tree Construction of Research Paper
PredCheck: Detecting Predatory Behaviour in Scholarly World
The evolving ecosystem of predatory journals: a case study in Indian perspective
The Rise and Rise of Interdisciplinary Research: Understanding the Interaction Dynamics of Three Major Fields–Physics, Mathematics and Computer Science
Understanding Popularity of Academic Entities: From Papers to Authors to Venues
Understanding the impact of early citers on long-term scientific impact
Citation sentence reuse behavior of scientists: A case study on massive bibliographic text dataset of computer science
ConfAssist: A Conflict resolution framework for assisting the categorization of Computer Science conferences
The role of citation context in predicting long-term citation profiles: An experimental study based on a massive bibliographic text dataset
PubIndia: A Framework for Analyzing Indian Research Publications in Computer Sciences